Serverless computing and containers are architectures that reduce overhead for the cloud hosted applications but they differ in many important ways. Containers are lighter than virtual machines, but serverless deployments are even lighter and scale more easily than containers. In this article we will discuss how serverless computing and containers differ with each other and when to use what?
Serverless
Traditional applications once developed need to deploy to servers in order to provide for customers. The problem with this approach is that it requires capacity planning, procurement of hardware, installation of software and making them ready for the application. This normally takes a week to months in setting up everything. It is time consuming and includes initial and running expenses.
With the introduction of Cloud with on-demand hardware minimizes the capacity planning and solving many issues. There will still be costs involved with CAPEX( Capital expenditure ) and OPEX( Operational expenditure ) but it decreases deployment time, no staff to manage hardware etc. In this article we will see what is serverless and how it can be used
Introducing Serverless
Serverless can be defined as “an approach that replaces long running machines with ephemeral compute power that comes into existence on request and disappears immediately after use”
Understanding Serverless
Serverless doesn't mean no server but a server which we don't need to manage. Instead of maintaining a server and running the services on that, we delegate the maintenance of the server to a third party and we concentrate on the development of the services that we need to run on those servers. Generally these third parties that manage the servers are Cloud vendors.
It would be very useful if we concentrate on the development of the service rather than managing a server. This is where serverless comes into the picture. Serverless or serverless computing is an execution model in which we run our services on a hardware provided by a Cloud vendor like Aws, Google or Azure. These hardware are managed by the cloud and resources are attached and detached to the server based on the requirements. The cost will be based on the amount of resources consumed by the service. This is what makes this different from other models. In normal cases, we buy a server and run our services on it. We manage the server like adding memory or cpu when required but in the serverless the management of the server is handled by the cloud including the resources and everything. All we need to do is to run our services on that.
As we already said that serverless does not require a pre-defined hardware for the execution of the application, but it is the role of the application to trigger an action which will cause the hardware to be created and application is executed on that. Once the execution is completed, the hardware is stopped until another action is triggered.
For instance, let's say we have a content management application where users upload an image to the articles that they write. If we are in a serverless architecture built with Aws Lambda , the image will get uploaded to the S3 bucket first and an event is triggered. The trigger will cause a Aws Lambda function written in multiple programming languages to resize the image and compress it to fit for displaying on multiple devices. The aws lambda code or functions that gets executed by the events triggered run on a hardware built on demand by the cloud provider. Once the execution is complete, the hardware is stopped and will be waiting for further triggers.
Function as a Service or Faas
When we say that servers are dynamically managed or created when we want to run the service, the idea is that you write your application code in the form of functions.
Faas or Serverless is a concept of Serverless computing where Software developers can leverage this concept to deploy an individual “function”, action, or piece of business logic. They are expected to start within milliseconds and process individual requests and then the process ends. The developer does not need to write code that fit the underlying infrastructure and he can concentrate on writing the business logic
One important thing to understand here is that When we deploy the function, we then need a way to invoke it in the form of an event. The event can be any time from API gateway ( http Request ), an event from another serverless function or an event from another service from cloud like S3.
The cloud provider executes the function code on your behalf. The cloud provider also takes care of provisioning and managing the servers to run the code upon invocation.
Serverless Providers
Most of the other major cloud computing providers have their own serverless offerings. Aws Lambda was the first serverless framework launched in 2014 and is the most matured one. Lambda supports multiple programming languages like Node.js, Java, Python and C# and the best part is this lambda integrates with many other Aws Services.
Google Cloud Functions is also available ,Azure functions from Microsoft and OpenWhisk is a Open source serverless platform run by IBM. Other Serverless options include Iron.io, Webtask etc.
Pros & Cons
Serverless provides many pros to developers and cons even. Here are few Pro’s
Pay only for what we use : the first pro is that we don't need to pay for the idle server time, and pay only for the time we execute our code on the server. The servers are kept idle or used for other executions.
Elasticity : with the serverless architecture, our application can automatically scale up to accommodate the spike in the application traffic and scales down when there are fewer users. The cloud Vendor will take the responsibility of scaling up/down the application based on the traffic.
Less time and money spent on Management : Since most of the infrastructure work like creating hardware, scaling up/down the service is taken care of by the vendor and with no hassle of managing the hardwares, it will help organizations to spend less money , time and resources giving them time to focus on the business.
Reduces development time and time to market : Serverless architecture gives enough time for the developers and organizations to focus on building the product. The vendor will take care of hardware, deployment of the services, managing and scaling them leaving organizations to focus on building the product and release it to the market. There are no operating systems they need to select, secure, or patch.
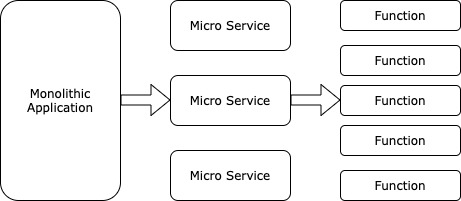
Microservice approach : Microservices are a popular approach where developers build modular software that is more flexible, modular and easier to manage then a monolithic application. With the same approach developers can work in building smaller, loosely coupled pieces of software that can run as functions.
Here are the Cons
Vendor Lock-in & Decreased transparency : this is one of the major concerns in moving to serverless in a cloud. The backend is completely managed by the vendor and once the functions are written, moving them to a different cloud can cause major changes to the application. Not just the code,the other services like Database, Access management , storage that are linked with the functions need a lot of time , money and resources in porting them to different clouds.
Supported programming Languages : Since the functions are written in certain programming languages not all languages have support. AWS Lambda directly supports Java, C#, Python, and Node.js (JavaScript), Google Cloud Functions operates with Node.js, Microsoft Azure Functions works with JavaScript, C#, F#, Python, and PHP, and IBM OpenWhisk supports JavaScript, Python, Java, and Swift.
There are some other programming languages like scala, Goland etc where support for serverless is coming and still work in progress.
Not suitable for Long running Tasks : Since the functions are event based in nature, this can be a best fit for long running tasks. The timeout limit on Lambda used to be 5 minutes, but as it was a major barrier for some applications in using serverless, it was increased and since Oct 2018 Lambda can run up to 15 minutes.
On other serverless platforms, it varies from 9 minutes to 60 minutes maximum. There are many use cases in general for long-running processes, such as video processing, big data analysis, bulk data transformation, batch event processing, very long synchronous request, and statistical computations which can’t be a best fit for serverless computing.
Potentially tough to debug : There are tools that allow remote debugging and some services (i.e. Azure) provides a mirrored local development environment but there is still a need for improved tooling.
Hidden Costs : Auto-scaling of function calls often means auto-scaling of cost. This can make it tough to gauge your business expenses.
Better Tooling : You now have a ton of functions deployed and it can be tough to keep track of them. This comes down to a need for better tooling (developmental: scripts, frameworks, diagnostic: step-through debugging, local runtimes, cloud debugging, and visualization: user interfaces, analytics, monitoring).
Higher Latency in responding to application events : since the hardware is set idle for quite some time and when we trigger to run a function, the server can take some time to wake up and run the function.
Learning Cure : Serverless does have a learning curve in defining our software in the form of functions. Converting our monolithic application into microservices and then to functions require deep understanding of the architecture and how they work.
Containers
Containers are a method of operating system virtualization that allow you to run an application and its dependencies in a resource isolated process. Containers contain both applications and all its dependencies that need to run properly including the system libraries, system settings and other files. Any Kind of application can be run in a container. A containerized application will run the same way no matter where it is hosted. Another advantage is that the container can easily be moved around and deployed wherever needed.
Containers are a solution to the problem of how to get software to run reliably when moved from one computing environment to another. This could be from a developer's laptop to a test environment, from a staging environment into production, and perhaps from a physical machine in a data center to a virtual machine in a private or public cloud.
Containers on the other hand will require hardware to run. We need to have a dedicated hardware to run the containers. It is our responsibility to build dedicated hardware and deploy containers on that.
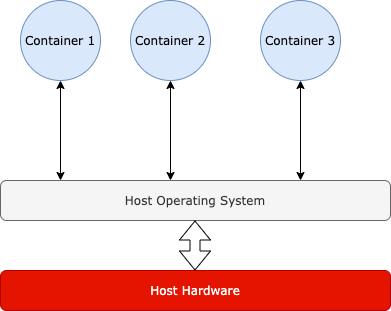
Containers work by partitioning a machine into separate user space environments such that each environment runs only one application and does not interact with any other environments unless defined so. The important thing over here is every user space environment ( Container ) will share the host kernel and hardware. The host kernel will be responsible for providing necessary memory, cpu and other hardware to the container.
Containers allow you to easily package an application code, Configurations and dependencies into easy to use building blocks that deliver environmental consistency, operational efficiency, developer productivity and version controlling. These containers give more granular control over resources giving improved infrastructure efficiency.
Pro’s and Con’s
Similar to other technologies, Containers also have Pro’s and Con’s. Here are the Pro’s
Increased Portability : the main advantage with containers is that we can combine the application and all its dependencies into a little package and run it anywhere. This provides a complete level of flexibility and portability. Applications running in containers can be deployed easily to multiple different operating systems and hardware platforms.
Vendor agnostic : Containers does not depend on any cloud or vendor. We can create images with all necessary applications and dependencies and run them anywhere with no dependency on any vendor.
Full control of application : Since teams are responsible for packaging applications and dependencies, they will have full control of the application packages.
Large and Complex : Large and complex applications can be packaged and run in a container.
Scalability : Since containers are under our control, containers can scale as much as you can based on your infrastructure.
Security Flexibility : Full Flexibility and Control with Containers in terms of setting policies, managing resources and security.
Less overhead : Containers require less system resources than traditional or hardware virtual machine environments because they don’t include operating system images.
More consistent operation : DevOps teams know applications in containers will run the same, regardless of where they are deployed.
Greater efficiency : Containers allow applications to be more rapidly deployed, patched, or scaled.
And Here are the Cons
Performance Overheads : Containers don’t run at bare-metal speeds. Containers utilize resources more efficiently than virtual machines but still have performance overheads due to overlay networking, interfacing between the container and the host system.
No graphical interface support : Docker containers were designed as a solution for deploying server applications that don’t require a graphical interface. While there are some creative strategies (such as X11 video forwarding) that you can use to run a GUI app inside a container, these solutions are clunky at best.
Management : Though containers can scale easily as much as you can, managing those scaled containers can be hard to maintain. Container orchestrators do the job for us by managing the containers and placement but still this is hard without an orchestration tool.
Security : security is the biggest problem with containers. Container does not have a Kernel and it depends on the host kernel to talk with Hardware. Security breaches can happen if unsecured things are running inside a container.
Not all applications benefit from containers : In general, only applications that are designed to run as a set of discrete microservices stand to gain the most from containers.
Monitoring : As an application grows, more and more containers are added. And these containers are highly dispersed, scattered, and constantly changing, thus making monitoring a nightmare.
Can Slow development process : Every time you make a change to your codebase, you’ll need to package the container and ensure all of the containers communicate with each other properly before deploying into production. You’ll also need to keep containers’ operating systems up to date with frequent security fixes and other patches.
Serverless Vs Containers
While both serverless and containers do have many things in common, there are few gaps between them. Here are the major differences between them,
Server Space : The first difference is where they run, Serverless computing actually runs on servers but it is up to the vendor to provision server space as it is needed by the application. No specific machines are assigned for a given function or application. On the other hand containers live on a machine that is preconfigured and set ready.
Deployment : Deploying a Function and running it will be taken care of by the Vendor itself. Whenever we trigger a function execution, the function is deployed to a server known to the vendor and function is executed. On the other hand, it is the responsibility of the developer to deploy the container and keep that available to run.
Elasticity : Scaling a function in serverless is taken care of by the vendor based on load. On the other hand, Scaling a container requires manual intervention by increasing the number of containers. With the introduction of Container orchestration platforms, this is taken care by the orchestration engine like kubernetes etc to scale the containers when load increases.
Pay only for what we use : The important advantage with the Serverless is the price. We pay only for what we use. When a function is triggered, we pay only for the amount of time, resources used for executing the function. On the container side, the price is more as we need to keep the container up and running no matter if it is being run or not.
Maintenance : Serverless architecture does not have any backend to manage. The vendor will take care of management and software updates for the servers that run the code. On the container side, it is the responsibility of the teams to keep Hardware updated, patched and maintained.
Testing : Testing the function on a serverless can be difficult as the backend environment is hard to replicate on local machines whereas containers can run on the local machines no matter where they are deployed,making it simple to test.
Scaling prices : Container technology enables you to scale your applications as much as you want. Going Serverless, that’s not always the case, as sometimes it may cause the size and memory restrictions.
Slow scaling : Scaling can be slower in containers when compared with serverless. Serverless scaling is done by the Vendor and containers scaling is by the application team. We need to define how scaling needs to be done in case of containers like resource scaling, load scaling etc.
Support for programming Languages : Serverless does not have support to all programming languages, AWS Lambda directly supports Java, C#, Python, and Node.js (JavaScript), Google Cloud Functions operates with Node.js, Microsoft Azure Functions works with JavaScript, C#, F#, Python, and PHP, and IBM OpenWhisk supports JavaScript, Python, Java, and Swift. Azure Functions works with JavaScript, C#, F#, Python, and PHP, and IBM OpenWhisk supports JavaScript, Python, Java, and Swift.
There are some other programming languages like scala, Goland etc where support for serverless is coming and still work in progress.
Containers can be built with any programming language available. All we have to do is to write code, package it along with libraries and run in containers.
Not suitable for Long running Tasks : Since the functions are event based in nature, this can be a best fit for long running tasks. The timeout limit on Lambda used to be 5 minutes, but as it was a major barrier for some applications in using serverless, it was increased and since Oct 2018 Lambda can run up to 15 minutes. On other serverless platforms, it varies from 9 minutes to 60 minutes maximum. There are many use cases in general for long-running processes, such as video processing, big data analysis, bulk data transformation, batch event processing, very long synchronous request, and statistical computations which can’t be a best fit for serverless computing.
Containers on the other hand can run any type of applications or tasks.
Development times : With the serverless, we only need to consider writing the code and rest will be taken care of by the vendor. On the other hand, containers do require additional work such as building the image, moving it to the registry
Monitoring : Monitoring capabilities for the serverless are provided by Vendor itself. How our function is performing, how much time it took to respond etc are given by the vendor tools itself. In Container,it is our responsibility to install a monitoring tool to capture all these details.
Which Architecture to Choose?
Serverless and Docker are not competing platforms, they are mutually supporting architectures of a dynamic world of Cloud computing. Both are used to deploy microservices but work for different needs.
When Can we use Containers?
Containers are best suited for running long processes where you need a high level of control over your environment and you have the resources to set up and maintain the application. Migrating monolithic legacy applications to cloud containers is the best suited way. We can split down these apps into containerized microservices and orchestrate them with an engine like kubernetes or swarm.
When can we use Serverless?
Serverless are best applied for applications that need to be ready to perform tasks but dont always need to be running. Serverless is ideal when development speed and cost minimization is paramount and if you don’t want to manage scaling concerns and infrastructure.
In simple terms, choose containers and container orchestrators when you need flexibility, or when you need to migrate legacy services. Choose serverless when you need speed of development, automatic scaling and significantly lowered runtime costs.
Can Serverless and Containers Work together?
No doubt, serverless and containers can work together. Both have strengths that can compliment others' weaknesses. We can build large, complex applications with container based microservice architecture but it can also handle some of the back end tasks such as data transfer, file backup, alerts triggering to serverless functions.
A simple implementation using Aws Fargate which is sort of hybrid between containers and serverless that can help alleviate some of the issues that each of technology presents. Fargate is a compute engine for Amazon ECS ( Elastic Container Service ) and EKS ( Elastic Kubernetes Service ) that lets us to run containers without having to manage servers. You don’t have to provision, configure, or scale virtual servers to run containers. Thus, Fargate combines the portability of containers with the elasticity and ease of use of serverless.

