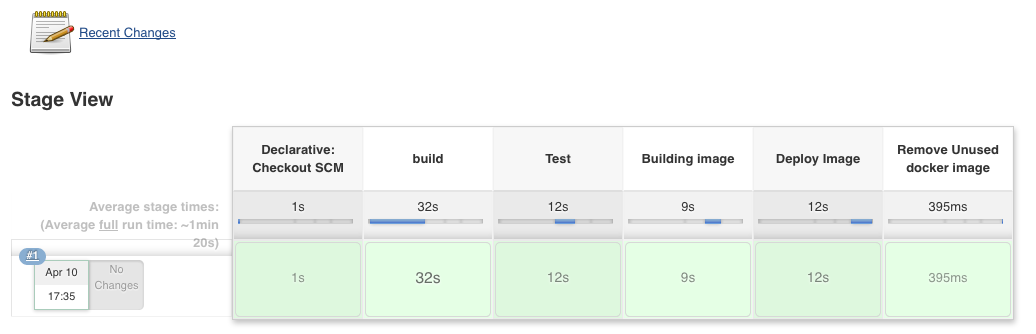
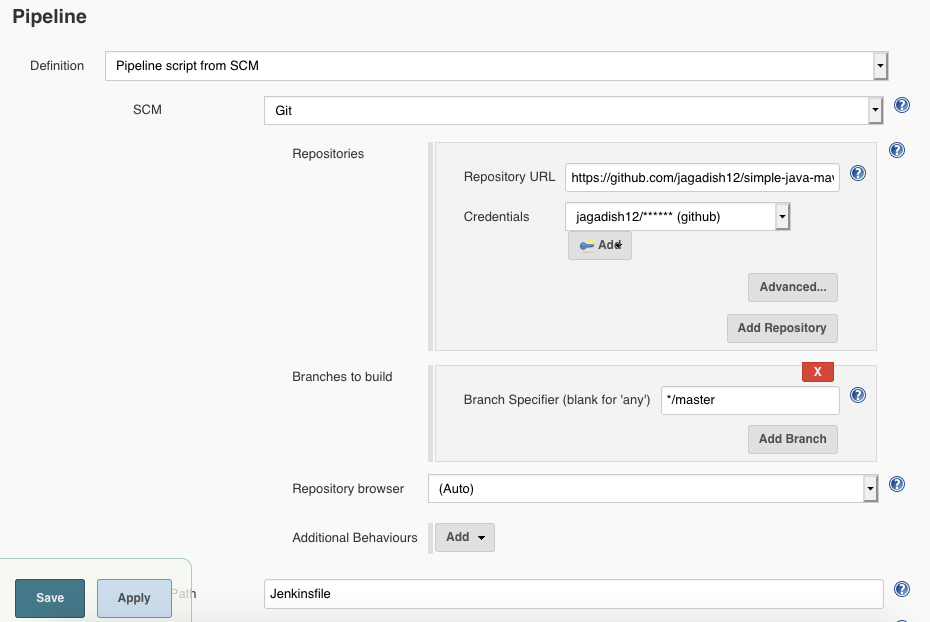
One of the basic steps of implementing CI/CD is integrating the SCM ( Source Code Management ) tool like git and github with CI tool. This saves time by building the source code when there is change done to the code.
In this article we will see how we can configure Github with Jenkins running on a Aws Instance. We will integrate jenkins and github in such a way that if there is any change made to the source code on Github, it will trigger a build on the Jenkins server.
Configure the Aws Instance and Install Jenkins on that server :
Create a seperate Security Group in for the jenkins server as below,
Open the Amazon EC2 console at https://console.aws.amazon.com/ec2/.
In the navigation bar, verify that US West (Oregon) is the selected
region.
In the left-hand navigation bar, choose Security Groups, and then click
Create Security Group : In Security group name enter WebServerSG and provide a description and Choose your VPC from the list.
In this article we will see how we can configure Github with Jenkins running on a Aws Instance. We will integrate jenkins and github in such a way that if there is any change made to the source code on Github, it will trigger a build on the Jenkins server.
Configure the Aws Instance and Install Jenkins on that server :
Create a seperate Security Group in for the jenkins server as below,
Open the Amazon EC2 console at https://console.aws.amazon.com/ec2/.
In the navigation bar, verify that US West (Oregon) is the selected
region.
In the left-hand navigation bar, choose Security Groups, and then click
Create Security Group : In Security group name enter WebServerSG and provide a description and Choose your VPC from the list.
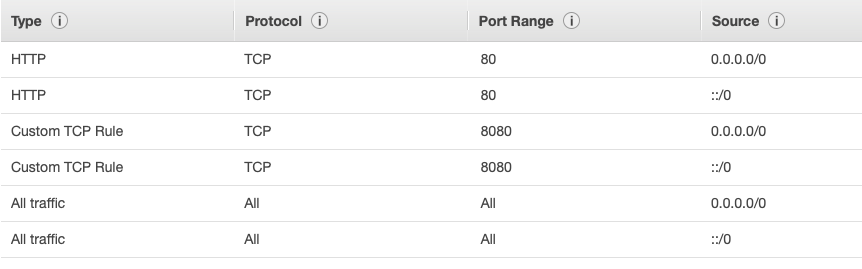
Create the rules in the inbound list of the Security Group as above.
While creating the instance,
Choose enable to “Auto-assign Public IP”.
choose the security group created above “WebSererSG”.
Once the instance is up and running , install java and jenkins.
Configure the Github plugin on the Jenkins Server
Once we install the github plugin go to Manage Jenkins -> Configure System and configure the plugin. We need to first configure the integration between jenkins running on our machine and the public github. One important thing we need to remember is that github can talk to servers running only public ip address. This is the reason why we have enabled the public ip while configuring the instance.
While creating the instance,
Choose enable to “Auto-assign Public IP”.
choose the security group created above “WebSererSG”.
Once the instance is up and running , install java and jenkins.
Configure the Github plugin on the Jenkins Server
Once we install the github plugin go to Manage Jenkins -> Configure System and configure the plugin. We need to first configure the integration between jenkins running on our machine and the public github. One important thing we need to remember is that github can talk to servers running only public ip address. This is the reason why we have enabled the public ip while configuring the instance.
Under the Configure System, add a Github Server. 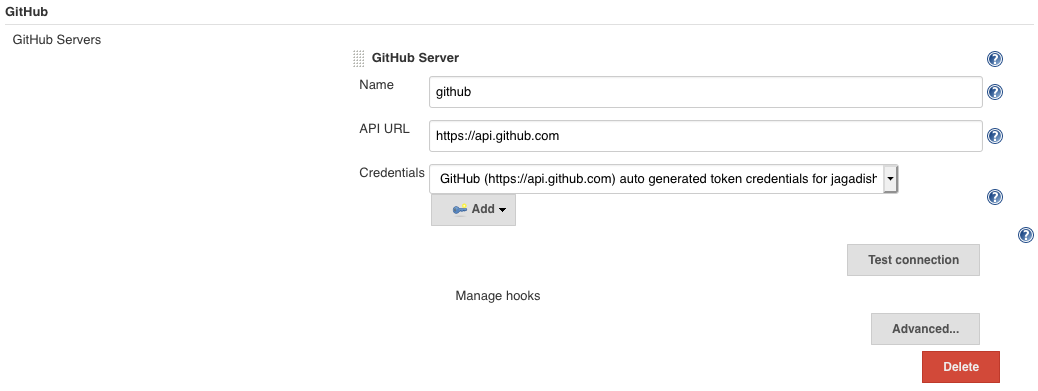
One another important thing to note is that the Github server does not accept credentials created using user name and password. For this we need to first we need to create a credential with the github username and password to login.
Under the Github Server section, click on the advanced button. Under this it shows a shared secret drop down. This will list the credential created in the above. Choose that and click on the “create token credentials”.
Under the Github Server section, click on the advanced button. Under this it shows a shared secret drop down. This will list the credential created in the above. Choose that and click on the “create token credentials”.
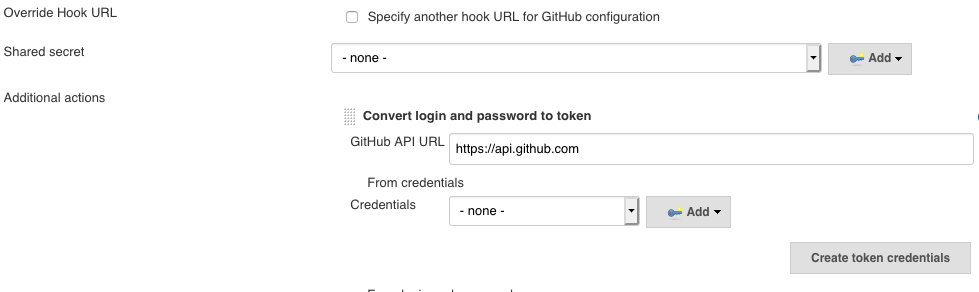
Once we click on the create token , it will create a token based credential in the jenkins server and the name will start with something Github. Now go back to the github server, and choose the credential created as token.
Another important thing that we need to do is to create a shared key. Now go to Credentials and create a secret key with any value. I have chosen the value "githubjenkins" and create a credential. Now this will used with the github Server in Configure System. Go back to Configure System -> under the Github Server configuration , click advanced and in the shared secret , choose the secret key credential created.

On the Github Side -
Go to the Github Repo -> Settings -> Webhooks
Payload URL: http://<IP address>:8080//github-webhook/ ( make sure you have tailing "/" at last, this is very important )
Content type : application/json
Secret : give the secret "githubjenkins" in here
For the event, choose “let me select individual events” and under that choose push and pull
Configure a Job on jenkins that will get triggered by committing to the Github repo: Configure any type of job but in order to get triggered by a github commit all we need to is to choose “GitHub hook trigger for GITScm polling” under the build triggers. We also need to configure the git with the same repo from which we want to trigger the hook. in my case iam triggering the webhook from the sampleTest project in github. on the Job side, i have to choose the SCM as git and provide this github repo details and credentials details to connect. If we dont do this git configuration we will not be triggered when we commit some thing on the github. this is a very important step.Check the box before this option and save your job.
Now commit a change on the Github side and see that job is triggered on the jenkins side.